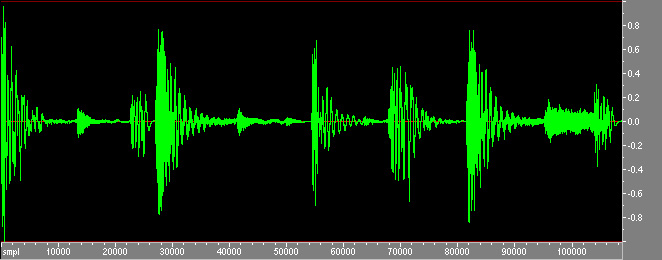
Analyse av testbeat.wav
Det jeg har gjort over, er å ta en trommerytme, vise hvordan den ser ut (waveform
og sonogram). For deretter filtrere trommerytmen inn i 6 forskjellig bånd (frekvensbånd),
og vise resultatet av dette. Grunne til at jeg gjør det er for å vise grafisk hvordan
jeg mener det er mulig å skille ut (stort sett) de enkelte lydene en trommerytme er
bygd opp på.
Denne trommerytmen er bygd opp av tre (hoved) instrumenter. Basstromme, hihat og
skarptromme. Dette er relativt greit for et menneske å høre, men for en datamaskin vil
det ikke være like logisk å dele opp rytmen slik. Hvis vi istdf. å se på instrumenter,
heller bare ser på det som lyder finner vi at rytmen er bygd opp av syv lyder:
basstromme1 (høy), basstromme2 (høy), basstromme2 (lav), hihat (lukket), hihat
(lukket & lav), hihat (åpen), skarptromme. Dette kan vi best se på det store
sonogrammet av hele bånnbredden, de følgende lydene finner vi cirka rundt
samplepunktene:
- basstromme1 (høy), 0, 54000
- basstromme2 (høy), 0, 66000,
- basstromme2 (lav), 22000, 102000
- hihat (høy & lukket) 0, 12000, 40000, 54000, 66000
- hihat (lav & lukket), 50000, 64000
- hihat (høy & åpen), 96000
- skarptromme, 26000, 80000
Det er kanskje ikke lett å forstå sonogrammet, men hvis du tenker at hihats ligger
høyt i frekvensområdet, og basstrommer veldig lavt nede gir det en viss peiling.
Den første toppen i sonogrammet består av tre lyder (jeg gjetter her, jeg har ikke laget
trommerytmen selv). Den består av basstromme1 + basstromme2 + hihat (lukket). Her kan jeg
allerede spå at jeg bare vil greie å skille ut to lyder i programmet, hihat og basstromme
(som egentlig er to forskjellige som blir tolket som en). Grunnen til det er at
jeg i mitt program forutsetter at lyder som blir spilt samtidig og skal oppfattes
som forskjellige, må ligge (hovedsaklig) i forskjellige frekvensspekter.
Uansett før jeg går videre med å forklare hvordan jeg tenker meg en mulig algoritmisk
løsning av problemet med å skille trommelyder, la meg peke på et vakkert lite eksempel
hvor en klart ser at to lyder spilles samtidig. Sjekk helt i slutten av
sonogrammet for orginalrytmen. Her ser vi to grafiske former, et rektangel som varer
ifra 96000-106000 og en 'hump' som begynner rundt 102000 og går helt til samplens
slutt. Dette er hihat (åpen) dvs: TIIiiiiissshhhh (rektangel), og basstromme2
(lav) dvs: boom ('hump'). Disse to lydene overlapper hverandre tidsmessig mens
i frekvensspekteret ser vi at de er godt adskilt, ergo: kan lett skilles.
|
Skille trommelyder
Kort fortalt tenker jeg meg at jeg deler opp en tromerytme som over, dvs. i en
rekke frekvensbånd, og analyserer hver enkel waveform hvor jeg leter etter start/stopp
for lyder. Etter å ha analysert hvert bånd, sammenligner jeg bånd som ligger ved siden
av hverandre i frekvensspekteret og ser om de har sammenfallende start/stopp resultater.
Hvis disse båndene har sammenfallende resultater legges deres smådeler av waveformen
isammen, og dette gjentas til det ikke er sammenfallende resultater.
Måten jeg tenker å skille start/stopp på, er enkelt og greit ved lage en noisegate-aktig
algoritme som trigges når signalestyrken går over et vist nivå, og trigges igjen når
signalet har sunket til under nivået. Hvis en lyd starter før en annen lyd er ferdig
avsluttet betyr det desverre at start/stopp detekteringen ikke vil bli helt riktig, men
det er som nevnt over problemet når vi har to signaler som 'bor' i samme frekvensområde.
Det kan nok lages en algoritme som 'gjetter' når en lyd egentlig er ferdig, vi kunne
f.eks brukt envelopen til lyden og forutsatt at lyden ble dempet naturlig, og utifra
det funnet stopp-punktet. Men vi har fortsatt da problemet med at den andre lyden vil
forsøpple den vi jobber med (og gjøre søking etter liknende lyd i en database
vanskeligere).
Etter at vi har sammenlignet de forskjellige bitene i de forskjellige frekvensbåndene,
og lagt isammen de som sansynligvis er av samme lyd, sitter vi igjen med endel sampler.
Poenget er nå at disse samplene (som forhåpentligvis er trommelyder) skal bli brukt
som søkekriterie i en database hvor vi vil lete etter liknende lyder (men som ikke er
filtrert).
Søking i database
For at vi skal kunne sammenlikne lydene ovenfra med 'rene' lyder som ligger i en database
må vi sammenlikne lyder på like vilkår. Ergo: vi må filtrere lydene som er i databasen
og sammenlikne dem etter de har mottatt samme frekvensbåndbegrensning som de enkelte
lydene vi har fra analysen. Et stort spørsmål her er: Vil dataen vi filtrer vekk være
den samme for lyden ifra analysen som ifra databasen? Til det kan jeg bare svare, vet
ikke, men jeg håper da det :)
At vi må sammenlikne lyder med samme filtrering krever at vi under beskrivelsen av
lydene til databasen filtrerer disse i alle bånd vi tenker oss nødvendige og deretter
kjører 'beskrivelses-algoritmen' på dem. Dvs. en sample har ikke bare en beskrivelse,
men flere, alt etter hvilke frekvensområder du ser på. De attributtene som vil bli
beskrevet for en trommelyd er til nå: frekvensspekter (gj.snitt), sonogram, envelope,
lengde, pitch (hvis det finnes). Om dette er nok til å finne en lyd som er lik en annen
vet jeg ikke, men det er jo en av grunnen jeg holder på med dette.
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}