
This figure shows commonly used representations when processing software languages, and the mappings between them.
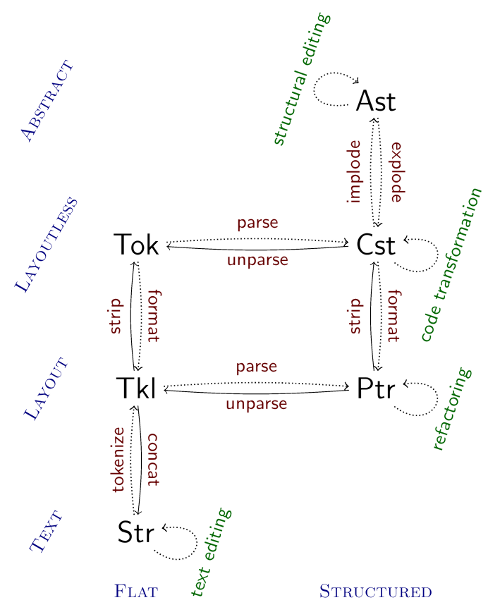
The left-hand side has flat, sequence-based representations (strings, token sequences) and the right-hand side has tree-based representations (concrete and abstract syntax trees).
The vertical axis indicates abstraction, with the more concrete representations at the bottom. ‘Layout’ in this sense includes things such as spaces and comments. We could also add extra layers for ‘layoutless with comments’ and ‘layoutless without comments’ (and vice-versa).
Mappings with solid arrows have a straight-forward universal definition, while dotted mappings depends on some kind of syntactic information.
The different artifacts are:
- Str
- Strings; sequences of characters.
- Tkl
- Sequences of tokens with layout.
- Tok
- Sequences of tokens without layout.
- Ptr
- Parse trees / concrete syntax trees with layout
- Cst
- Parse trees / concrete syntax trees without layout
- Ast
- Abstract syntax trees
There are sensible universal defaults for the implode mapping from Cst to Ast, but with significant potential for customisation of the Ast representation.